
When I was first introduced to the idea of data meshes, I thought it was one of those incredibly brilliant ideas which simply took someone clever enough to look at a common problem from an uncommon perspective.
According to Starburst.io, data mesh is a new approach based on a modern, distributed architecture for analytical data management. It enables end users to easily access and query data where it lives without first transporting it to a data lake or data warehouse. The decentralized strategy of data mesh distributes data ownership to domain-specific teams that manage, own, and serve the data as a product.
There are many very good articles on data meshes such as this one by Barr Moses, CEO of Monte Carlo, titled What is a Data Mesh — and How Not to Mesh it Up. I won’t duplicate the details common in every article about data meshes. Rather I want to discuss a significant danger of data meshes that is not being addressed today.
This danger is how the challenge of data privacy within data sciences becomes an absolute nightmare if a data mesh is implemented without a corresponding evolution in how data privacy is implemented. So, let’s discuss how to avoid this pitfall and come out way better than where you started.
To start, we’ll review the basic structure of a data mesh. The diagram below was recreated based on the Barr Moses’s post:
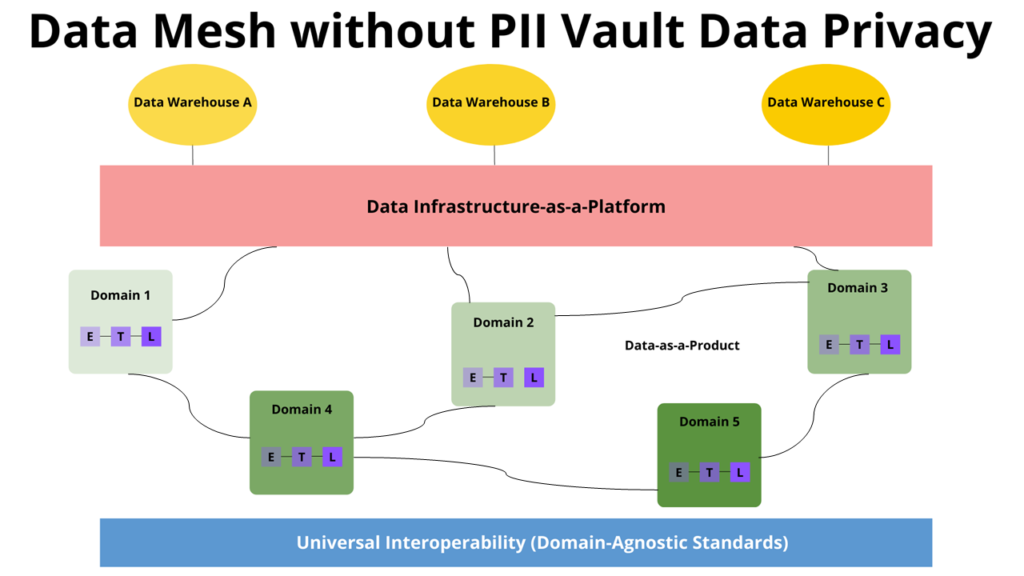
From the bottom up, it starts with a Universal Interoperability layer. Consider this the internal standards each domain must implement to deliver their data as a product.
The different domains appear on the next level up. Each domain holds responsibility for delivering their data as a product to other domains and to the central data repository. Within the domains, data is ETLed (Extracted, Transformed and Loaded). This basically takes data from one system, configures it so it can be loaded into another system, and then actually loads it into that other systems.
Data Infrastructure-as-a-Platform sits at the top of the architecture. It provides a standard, self-serve model by which data consumers and domains may either push their data to a warehouse or request data from a warehouse.
The beauty of a data mesh is its simplicity. It mirrors how individual business domains operate within an organization on a non-technical level. By using this same internal structure, a data mesh shifts the responsibility for providing data critical to an organization’s operations from large, centralized groups to small teams (domains). The efficiency and effectiveness come from the reality that the large, central teams often have only a shallow understanding of domain level data while the domains know their data intimately.
This clean, simple, and elegant solution deserves all the attention it currently receives.
Why is a Data Mesh so Risky for Data Privacy?
It’s because the very challenging task of implementing and enforcing data privacy grows exponentially for every domain in a de-centralized data mesh.
Specifically:
Data Privacy is Not Optional
We are all aware data breaches, and the exposure of customer data, have become a daily occurrence. The risk of being the target of a sophisticated cyber-attack increases with the amount of personal level data an organization maintains. While no one is immune, healthcare, and financial services are the largest targets. The potential costs of exposure, per record, have been rising yearly and are now estimated to be at $180. (Source: Cost of a Data Breach Report 2021 | IBM)
Data Privacy is Not Easy
Data privacy is a highly specialized area, and it is hard enough for large, centralized groups to implement properly. When you delegate this responsibility from one central team to each domain, then your challenge grows exponentially. What used to be handled by one (hopefully) knowledgeable and centrally located team is now distributed to every domain. With the dire shortage of people knowledgeable enough about data privacy to ensure an organization is not subject to significant consequences, what are the chances of anyone having enough experts to distribute to each domain?
Suddenly, the potential benefits of a data mesh become less compelling when compared to the potential liabilities.
Manual Processes Cannot Scale
An unfortunate reality is many, if not most organizations still rely heavily on manual processes and NDAs to cover their liability and to enforce data privacy. If you have ever been in these types of situations where you needed to negotiate access to data and felt like you were signing your life away just to get it, you likely know what I mean.
Now imagine that process having to scale dozens, if not hundreds, of domains in a node structure like a data mesh. Each domain becomes responsible for adhering to an international spaghetti bowl of data privacy regulations and industry standards. Differential privacy, encryption and tokenization do not have the power or flexibility to solve this problem.
The question is not if there will be failures but how long it will take for these failures to occur and how large the consequences will be.
The Organization Still Does Not Get What It Wants
The real rub is when data finally reaches each of the various data warehouses or data lakes without an evolved data privacy solution, it is still not going to be as safe, reliable, or useful as it could be. The data will be what we call ‘Dumb anonymous data,’ meaning it is good for aggregation but little else. Either that or it will have too many direct identifiers. Either way, the result either leaves the organization open to all sorts of data privacy related consequences or limits their use of the data which is counter to the goals of the data mesh.
What is the Solution?
If I am scaring you away from considering a data mesh for your organization, take heart, there is an answer. That answer is as clean and elegant as the data mesh structure itself.
To effectively deliver data privacy within a data mesh, you must integrate a modern, robust, and scalable data privacy solution into your architecture.
Integrate Data Privacy with Your Data Mesh
This sounds complicated but it is quite simple. Implementing a data mesh with integrated data privacy will not add to your risk or implementation timeline. In fact, not only can it speed things up, but it is also available today.
Anonomatic PII Vault™ , with its node-based deployment model, is a perfect fit for a data mesh. The diagram below shows how neatly the PII Vault solution fits into the data mesh architecture.
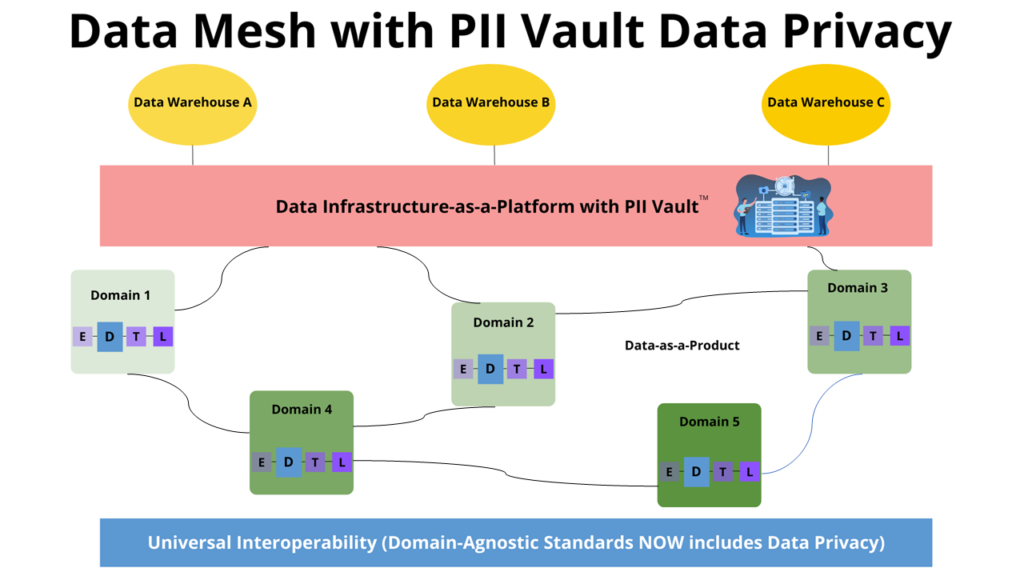
Anonomatic solves the data privacy problem in three simple steps:
Step 1: Include a Universal Interoperability Data Privacy strategy
There will always be some set of standards to which each domain must adhere to in fulfilling their Data-as-a-Product mission. Added to these standards will be the requirement to include data privacy into their processes. For each data product this is usually one simple step which is easily automated. We call this Passthrough Anonymization.
Step 2: Add PII Vault to Data Infrastructure
Anonomatic PII Vault is added to the infrastructure layer. The PII Vault enables using anonymous data as if it were identified. With PII Vault, different sets of anonymous data may be combined at the individual level without the need for any direct identifiers being present in the data. This is done through a process we call Poly-Anonymization™. Poly-Anonymization enables de-identified data to be ‘Smart anonymous data’. With smart (poly-anonymized) data you get as much value out of it as if it were fully identified, but with none of the risk.
This is such a unique and counter-intuitive capability that it bears restating. PII Vault allows two or more completely anonymous datasets, from different domains or even different organizations, to be joined at the individual level without the data sources ever having to share their fully identified data.
Step 3: ETL Becomes EDTL
This leads us to the step where each domain serves up their data as a product. Here the Extract-Transform-Load process, which is a foundation of data science and reporting endeavors everywhere, evolves and becomes Extract-Deidentify-Transform-Load.
The data is de-identified via Passthrough Anonymization with the help of a de-identification ruleset. The de-identification ruleset can be established organization-wide or defined individually. Either way the staff responsible for managing the domain can implement those rules with a clean and simple one-time configuration. Once configured, the rest may be completely automated. This ruleset is known as a PII Vault Schema.
An example schema is below:
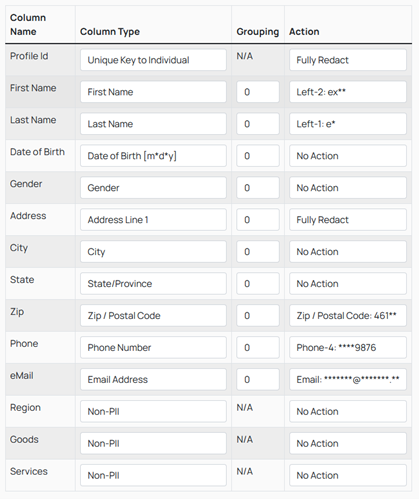
In this simple example, the data represents the amount of goods and services purchased, by region, from customers. This information includes a lot of very risky Personal Identifiable Information (PII). However, once the PII Vault de-identifies and renders the data safe, it becomes ‘smart anonymous data’. Smart anonymous data can be joined, merged, matched, and shared across disparate datasets to achieve organizational goals and never puts data privacy at risk because no personal identifiers are present in the data.
With PII Vault, not only are the key identifiers fully redacted, but any value may be partially redacted. The user decides what actions are applied to each data field. As we like to say, “Hackers cannot steal what you do not have.”
Conclusion
The data revolution has been going on for quite a while and there is zero chance it is going to stop, or even slow down, anytime soon. In fact, the data revolution pace continues to accelerate. Therefore so many people are looking into data meshes. This new structure promises to bring increased speed, agility, and bandwidth to the data collection process.
With PII Vault, domain-based data collection not only is data privacy compliant, but it also enables organizations to acquire data they could not easily access or quite often, were denied access to completely. After all, how much more willing would you be to share completely anonymous data compared to fully identified data?
Are you thinking about implementing a data mesh and want to learn exactly how your organization can protect itself from data privacy violations? Please contact us, we will be happy to show you just how quick and easy the answer is.
Recent Comments